
O Retrato do Mercado em 2025
A previsibilidade é o alicerce de qualquer ambiente de missão crítica. No entanto, os dados brutos da pesquisa Postgres em Foco 2025 revelam um cenário desafiador: 20,8% das empresas brasileiras ainda operam com o PostgreSQL 12 ou versões anteriores em produção.
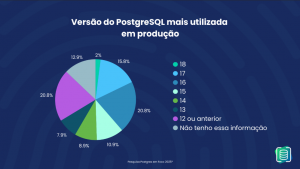
Com o PostgreSQL 12 atingindo o seu estágio de End of Life (EOL), essa permanência deixa de ser uma escolha técnica de estabilidade e passa a ser um risco estratégico de continuidade de negócio.
O Risco Real da Inércia Operacional
Manter uma versão descontinuada significa operar sem o suporte do grupo global de desenvolvimento do PostgreSQL. Para uma pessoa especialista ou gestora técnica, isso se traduz em três frentes de risco:
- Segurança: Ausência de patches para novas vulnerabilidades (CVEs).
- Conformidade: Dificuldade em manter certificações de segurança de dados em ambientes defasados.
- Custo de Oportunidade: Perda de eficiência em relação às otimizações de performance introduzidas nas versões 13 a 18.
Upgrade como Alavanca de Maturidade
Dentro da Matriz de Maturidade PostgreSQL, o processo de atualização não deve ser encarado como um “mal necessário”, mas como uma evolução planejada.
- Pós-v12: Migrar para versões recentes permite acessar melhorias críticas em particionamento e na deduplicação de índices B-tree, o que reduz diretamente o consumo de storage e melhora o tempo de resposta.
- Visão Sistêmica: O upgrade é a oportunidade de realizar um Health Check profundo, identificando gargalos e desperdícios que muitas vezes são mascarados por versões antigas.
Checklist Tático: Como sair do Postgres 12 com Segurança
Para garantir que a migração seja previsível e eficiente, a Timbira recomenda focar nos seguintes pontos de controle:
- Planejamento de Salto (Jump): Avaliar se a migração será direta para a versão mais recente (v18) ou se há dependências arquiteturais que exigem passos intermediários.
- Análise de Compatibilidade: Validação de extensões e plugins do ecossistema que podem ter mudado o comportamento. Revisão das notas de lançamento que trazem informações sobre regressões e pontos de atenção a considerar no planejamento. Validação de Performance: utilizar o EXPLAIN e métricas de observabilidade para comparar o comportamento de consultas críticas entre a versão 12 e a nova versão.
Do Operacional ao Estratégico
Os dados da pesquisa mostram que a “Dificuldade na atualização” é um dos maiores entraves do mercado. No entanto, a evolução do DBA para o papel de Data Sustainability Engineer (DSE) exige essa transição do operacional reativo para o tático-estratégico.
Sair do Postgres 12 é o primeiro passo para garantir que o seu banco de dados não seja apenas uma ferramenta técnica, mas um ativo que impulsiona a inovação e a vantagem competitiva da sua empresa.
Conte conosco!
Precisa de apoio para planejar sua migração? Entre em contato com a Timbira. Nossos especialistas podem te ajudar a planejar e executar a migração com segurança, sem complicações e com o mínimo de interrupções.






